

How To Load The Data Files Into Gpu Memory
This post is the beginning installment of the serial of introductions to the RAPIDS ecosystem. The series explores and discusses various aspects of RAPIDS that allow its users solve ETL (Extract, Transform, Load) issues, build ML (Machine Learning) and DL (Deep Learning) models, explore expansive graphs, process geospatial, signal, and organization log data, or use SQL language via BlazingSQL to process data.
RAPIDS framework was introduced in late 2018 and has since grown essentially, both, in terms of popularity as well as characteristic richness. Modeled subsequently the pandas API, Information Scientists and Engineers can apace tap into the enormous potential of parallel computing on GPUs with just a few code changes.

In this post, we will provide a gentle introduction to the RAPIDS ecosystem and showcase the most common functionality of RAPIDS cuDF, the GPU-based pandas DataFrame analogue. We will likewise introduce some of the newer and more advanced capabilities of RAPIDS in later segments: NRT (near real-time) data streaming, applying BERT model to extract features from system logs, or calibration to clusters of hundreds of GPU machines, amidst others.
cuDF is a information science building block for RAPIDS. Information technology is an ETL workhorse allowing building information pipelines to process information and derive new features. Being function of the ecosystem, all the other parts of RAPIDS build on top of cuDF making the cuDF DataFrame the common building block. cuDF, just similar whatever other office of RAPIDS, uses CUDA backed to ability all the GPU computations. However, with an piece of cake and familiar Python interface, users do not need to interact direct with that layer.
To help get familiar with using cuDF, we provide a handy cheat sheet that can be downloaded hither: cuDF-cheat sheet, and an interactive notebook with all the electric current functionality of cuDF cheatsheet here.
Familiar interface for GPU processing
The core premise of RAPIDS is to provide a familiar user feel to popular data science tools and then that the ability of NVIDIA GPUs is easily accessible for all practitioners. Whether yous're performing ETL, building ML models, or processing graphs, if yous know pandas, NumPy, scikit-learn or NetworkX, you will feel at home when using RAPIDS.
Switching from CPU to GPU Data Science stack has never been easier: with equally fiddling change as importing cuDF instead of pandas, you lot can harness the enormous ability of NVIDIA GPUs, speeding upwards the workloads 10-100x (on the low end), and enjoying more productivity – all while using your favorite tools. Check the sample lawmaking beneath that presents how familiar cuDF API is to anyone using pandas.
import pandas as pd import cudf df_cpu = pd.read_csv('/data/sample.csv') df_gpu = cudf.read_csv('/data/sample.csv') Loading data from your favorite data sources
Reading and writing capabilities of cuDF accept grown significantly since the commencement release of RAPIDS in October 2018. The information can exist local to a automobile, stored in an on-prem cluster, or in the cloud. cuDF uses fsspec library to abstruse most of the file-system related tasks so yous tin can focus on what matters the about: creating features and building your model.
Thank you to fsspec reading data from either local or cloud file organization requires just providing credentials to the latter. The case below reads the same file from two different locations,
import cudf df_local = cudf.read_csv('/data/sample.csv') df_remote = cudf.read_csv( 's3://<bucket>/sample.csv' , storage_options = {'anon': True}) cuDF supports multiple file formats: text-based formats like CSV/TSV or JSON, columnar-oriented formats like Parquet or ORC, or row-oriented formats like Avro. In terms of file organisation support, cuDF can read files from local file system, deject providers similar AWS S3, Google GS, or Azure Blob/Data Lake, on- or off-prem Hadoop Files Systems, and besides directly from HTTP or (Due south)FTP spider web servers, Dropbox or Google Drive, or Jupyter File System.
Creating and saving DataFrames with ease
Reading files is non the merely way to create cuDF DataFrames. In fact, there are at least iv means to do and then:
From a list of values yous can create DataFrame with 1 cavalcade,
cudf.DataFrame([1,two,3,iv], columns=['foo']) Passing a dictionary if you want to create a DataFrame with multiple columns,
cudf.DataFrame({ 'foo': [i,2,iii,iv] , 'bar': ['a','b','c',None] }) Creating an empty DataFrame and assigning to columns,
df_sample = cudf.DataFrame() df_sample['foo'] = [one,2,3,4] df_sample['bar'] = ['a','b','c',None] Passing a listing of tuples,
cudf.DataFrame([ (one, 'a') , (2, 'b') , (3, 'c') , (iv, None) ], columns=['ints', 'strings']) You can also catechumen to and from other memory representations:
- From an internal GPU matrix represented as an
DeviceNDArray, - Through DLPack memory objects used to share tensors betwixt Deep Learning frameworks and Apache Pointer format that facilitates a much more convenient way of manipulating retention objects from various programming languages,
- To converting to and from pandas DataFrames and Serial.
In addition, cuDF supports saving the data stored in a DataFrame into multiple formats and file systems. In fact, cuDF tin store information in all the formats it can read.
All of these capabilities brand it possible to get up and running chop-chop no matter what your job is or where your data lives.
Extracting, transforming, and summarizing information
The fundamental data scientific discipline task, and the one that all data scientists complain about, is cleaning, featurizing and getting familiar with the dataset. We spend 80% of our time doing that. Why does it take and then much time? One of the reasons is because the questions we ask the dataset have also long to answer. Anyone who has tried to read and process a 2GB dataset on a CPU knows what we're talking near. Additionally, since we're human and nosotros make mistakes, rerunning a pipeline might quickly plow into a total day exercise. This results in lost productivity and, likely, a java addiction if we take a look at the chart below.
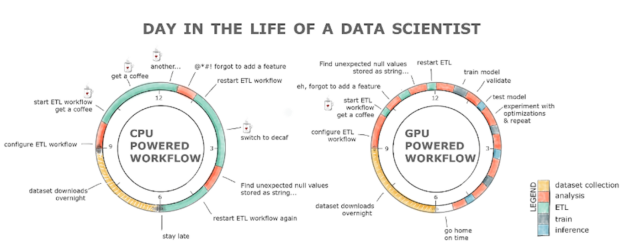
RAPIDS with the GPU powered workflow alleviates all these hurdles. The ETL stage is normally anywhere between 8-20x faster, so loading that 2GB dataset takes seconds compared to minutes on a CPU, cleaning and transforming the data is besides orders of magnitude faster! All this with a familiar interface and minimal code changes.
Working with strings and dates on GPUs
No more 3 years ago working with strings and dates on GPUs was considered virtually impossible and beyond the achieve of low-level programming languages like CUDA. After all, GPUs were designed to process graphics, that is, to manipulate large arrays and matrices of ints and floats, not strings or dates.
RAPIDS allows you to not but read strings into the GPU retentiveness, merely also excerpt features, process, and dispense them. If you are familiar with Regex then extracting useful information from a document on a GPU is now a trivial chore cheers to cuDF. For instance, if you want to find and extract all the words in your certificate that lucifer the [a-z]*menstruation blueprint (like, datamenses, piece of workmenstruum, or menstruum) all you need to practise is,
df['string'].str.findall('([a-z]*menstruation)') Extracting useful features from dates or querying the data for a specific flow of time has become easier and faster thanks to RAPIDS as well.
dt_to = dt.datetime.strptime("2020-10-03", "%Y-%m-%d") df.query('dttm <= @dt_to') All in all, RAPIDS has changed the game when information technology comes to data processing, and other tasks of data scientists, non but on a local GPU box, just also at scale in data centers. Queries that used to take hours or days to process take minutes to finish, resulting in increased productivity and a lower overall toll.
Meet it and try it for yourself at app.blazingsql.com and download the cuDF cheatsheet!

How To Load The Data Files Into Gpu Memory,
Source: https://developer.nvidia.com/blog/pandas-dataframe-tutorial-beginners-guide-to-gpu-accelerated-dataframes-in-python/
Posted by: burkemasimed.blogspot.com
0 Response to "How To Load The Data Files Into Gpu Memory"
Post a Comment